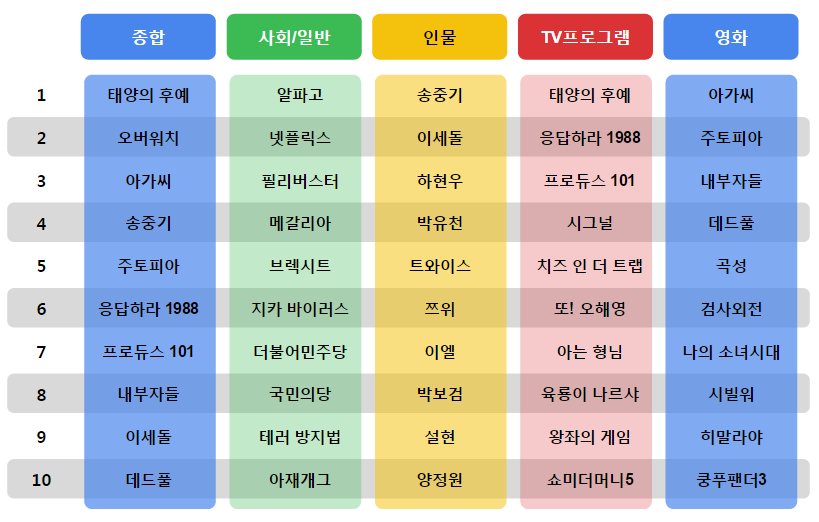
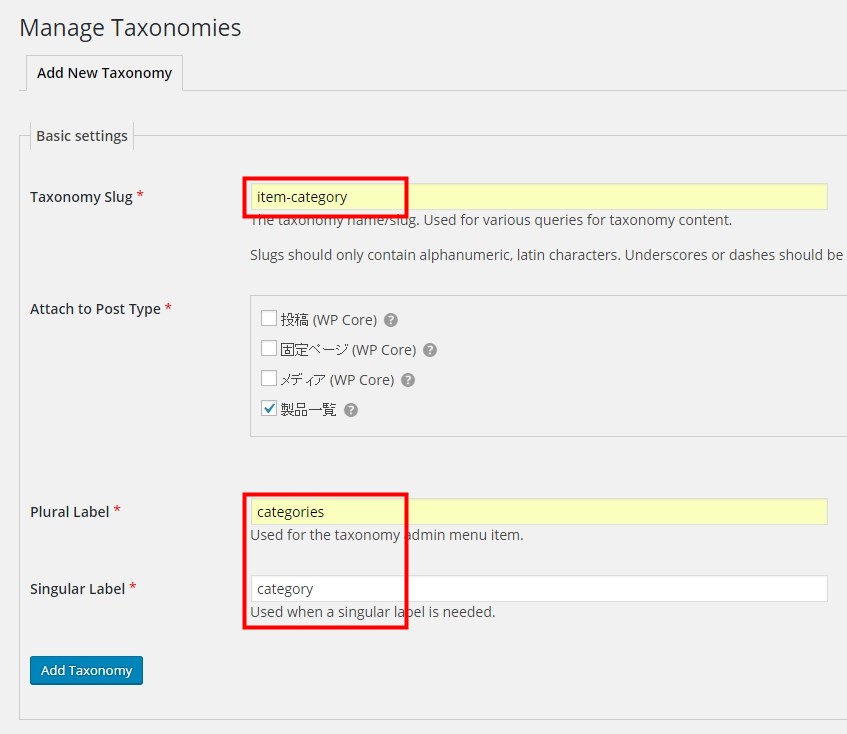
先月、Googleのセミナーに行ってきたのでその時に取ったメモです。
行ってきたのはGoogle Cloud Platform(gcp)のCP100Aというセミナーで、沢山あるGoogleのクラウドサービスの概要を1日で教えてもらえる講座でした。
全機能を浅く広く全体的に紹介するセミナーなのですが、gcpを初めて使う人や、BigQueryやAppEngineなど一部の機能は使っているけど概要はあまり理解できてない人にはお勧めな内容でした。
項目によって細かく書いている部分と、雑な部分がありますが、セミナーの説明が雑だったわけではなくメモが取り切れなかった(集中して聞きたいor興味がない項目)為です。
Google Cloud Platformの基本について
gcpのアカウントについて
billingアカウントと、プロジェクトアカウントがある
billingアカウントは課金のもので、プロジェクトを跨げる
プロジェクトIdについて
プロジェクトIDは変更できず、世界中でユニークである
コマンドラインで操作する場合は、通常プロジェクトIDを使う
プロジェクトの権限について
権限は大きく分けて4つある
Owner: プロジェクトの作成者がデフォルトでOwnerになる
なんでもできる
インスタンスの追加・削除
ユーザの招待
他ユーザへの権限追加
など
Editor: リソースの操作が可能
他のユーザへの権限や、プロジェクトの削除はできない
Viewer: 参照専用のユーザ
Billing: 課金を管理するもの
プロジェクトをまたいで所属可能な権限
経理の人とかを入れておくとよいかもしれない |
Owner: プロジェクトの作成者がデフォルトでOwnerになる
なんでもできる
インスタンスの追加・削除
ユーザの招待
他ユーザへの権限追加
など
Editor: リソースの操作が可能
他のユーザへの権限や、プロジェクトの削除はできない
Viewer: 参照専用のユーザ
Billing: 課金を管理するもの
プロジェクトをまたいで所属可能な権限
経理の人とかを入れておくとよいかもしれない
通常、1つのアカウントにOwner権限のユーザは2人以上いた方が良い
Billingを除いて、プロジェクト単位の権限となる。
IAMについて
プロジェクト単位ではなく、もう少し細かめに権限管理したい場合にはIAMを利用する
(たとえばgcpは操作できないが、bigqueryはアクセス可能など)
IAMはリソース単位で権限を指定可能となる
例えば、gcpのインスタンスを削除、一覧取得したい場合は下記の権限を与えるといったことが可能
compute.instances.delete
compute.instances.list |
compute.instances.delete
compute.instances.list
IAMはGoogleアカウントや、Google Groupに紐づけることができる
部署単位で権限管理する場合はGoogle Groupで管理すると便利
IAMのリソース階層
1つの案件に関して、複数の(gcp上の)プロジェクトを作ることができる
例えば、1つの案件に対して、開発環境・ステージング・本番環境で3つgcpのプロジェクトを作るなど
“案件”の事をgcpではOrganaizationと呼んでいる
サービスアカウント
gcpのリソースは、人がGUI経由で操作するだけでなく、プログラムからAPI経由でアクセスすることも多い
このような場合のために、サービスアカウントというものがあります
リソースを作ったときに自動的にサービスアカウントが作られてたりする
サービスアカウントは、メールアドレスの形式になっていて、下記のようなルールになっている
project_number@developer.gserviceaccount.com
project_id@developer.gserviceaccount.com
プロジェクトを作ると、自動で”Compute Engine default service account”というサービスアカウントが1つ作られる
このアカウントは、gcpコンソールのIAMと管理->サービスアカウントから確認することができる
権限は、すでにあるサービスアカウントに付与することもできるし、”特定のバッチだけ限られた権限を付与したいので専用のサービスアカウントを作る”といった使い方も可能
また、サービスアカウントを利用することで、プロジェクトを跨いで権限付与することができる
gcpへのアクセス
gcpへのアクセスには大きく3つある
- webのgcpコンソールからGUIで操作する
- cloud sdk利用したコマンドライン操作
cloud sdkが手元のPCにインストールされていない場合は、cloud shellを使うとweb画面からアクセス可能
- RESTベースのAPI経由でアクセスする |
- webのgcpコンソールからGUIで操作する
- cloud sdk利用したコマンドライン操作
cloud sdkが手元のPCにインストールされていない場合は、cloud shellを使うとweb画面からアクセス可能
- RESTベースのAPI経由でアクセスする
ユーザからみると3つありますが、最初の2つは裏でREST APIを実行している
REST APIを各種言語から使いやすくしたSDKも、もちろん用意されている
注意点としては、プロジェクトの追加・削除はguiからしかできない
また、細かな操作は、慣れるとコマンドラインから実行すると便利
cliのテストとして、例えばcloud shellから以下のコマンドを実行してみると、VMの一覧やクラウドストレージのバケット一覧を確認できたりする
gcloud compute instances list
gsutil ls |
gcloud compute instances list
gsutil ls
オプションなしでglcoudコマンドだけ打って実行すればヘルプが出るので、オプションは暗記しなくても大丈夫
Rest API
JSONベースでやり取りができる
API Explorer
簡単にRest APIをテストできる
https://developers.google.com/apis-explorer/#p/
Rest APIベースで開発中の場合はかなり便利
クライアントライブラリ
認証処理を簡単に実装できる
プログラムからアクセスする場合は、このライブラリを使うと便利
Google Cloud Client Libraries
コミュニティ主導で、手作業で作られているライブラリ
使いやすさはこちらが多少よいが、対応が遅い
Google APIs Client Libraries
REST APIから機械的に生成されているライブラリ
ちょっと使いづらいが、複数の言語が用意されている
新しい機能は、こちらの方が速く対応される
最初はちょっと面倒だが、慣れるとこちらの方が良い |
Google Cloud Client Libraries
コミュニティ主導で、手作業で作られているライブラリ
使いやすさはこちらが多少よいが、対応が遅い
Google APIs Client Libraries
REST APIから機械的に生成されているライブラリ
ちょっと使いづらいが、複数の言語が用意されている
新しい機能は、こちらの方が速く対応される
最初はちょっと面倒だが、慣れるとこちらの方が良い
AppEngineとデータの保存について
Google App Engine とデータストア
Google App EngineはPaaSサービス
サーバ構築やスケーリングの管理を行う手間がない
最近では、モバイルアプリのバックエンドとしても使われている
1日の無料枠があり、延べで28時間分までのCPUリソースであれば無料で利用可能
なので、VMが1台で収まるような小さなサービスなら無料で運用可能
AppEngineの環境
AppEngineの環境には大きく以下の2つがある
Google App Engine Standard Environment
Google App Engine Flexible Environment
Standard Environmentとは
開発、テストが可能なSDKがある
コマンド1つで本番にデプロイできる
ローカルなファイルに保存できない
リクエストは60秒以内に返す必要がある
関連する知識
タスクキュー
重い処理を非同期で実行できる
スケジュールドタスク
Cronのようなバッチ処理ができる
Flexible Environmentとは
現在ベータ版として提供されている
Node.jsなど、任意の言語で開発でき、環境の制限を取っ払える
Standard EnvironmentはBogueというコンテナサービスをベースにしているが、Flexible EnvironmentはDockerコンテナベースで動作する
1VMあたり1コンテナになるため、Standard Environmentほどは費用的に効率が良くない
Google Cloud Endpoints
APIの自動生成などを行ってくれるサービス
デフォルトでOAuth2.0ベースの認証がサポートされている
API単体でのテストが行いやすく、問題がある場合にも切り分けが行いやすい
Google Cloud Datastore
KVSベースのストレージ
スケールアウトは自動で行ってくれる
ストレージについて
Cloud Storage
ファイルのアップ・ダウンロードができる
実際はファイルシステムではないので、Windowsの共有フォルダのような使い方はできない
※Cloud strage Fuseを使うとLinuxならFileSystemとしてマウントは可能
インターネット越しのストレージなので、当然ながらローカルのストレージよりは遅い
Cloud strage Fuseはまだ実験的な実装なので、実用レベルではない
データの可用性は高いので、ハードウェア故障に備えたバックアップは不要(操作ミス対策のバックアップはもちろん必要)
マルチリージョンタイプの保存エリア(バケット)を作成すると、データセンターが1つ丸ごとダウンしても大丈夫なレベルでバックアップが取られる
Cloud Storageは、信頼性・パフォーマンス・費用に応じて複数の選択肢がある
Standard Storage
本番環境で使えるレベルのもの
DRA
少しパフォーマンスが悪いが、安い
Nearline strage
バックアップ向け
月に1回しかアクセスされないようなデータに向いている
非常にアクセスが多い場合は後述するCDNサービスも併用花王
Bigtable
get/putが高速に行える、KeyValueベースのストレージ
マネージドサービスとして利用できる
SQLのような形での検索処理は行えない
ApacheのHBaseはこのBigTableを元にしている
APIもHBaseと互換性があるので、HBaseクライアントも使用可能
ストリーミングインサートもがおこなえ、バッチ処理でデータ登録も可能
他のサービス(DatafrowやDataprocなど)と連携できる
Croud SQL
MySQLサービスのGoogle cloud版
マネージドサービスなので、パッチ当てなどの面倒な管理は不要
第一世代と第二世代があり、第一世代の時は遅かった(100Query/sec程度しか出ず、ストレージ容量も500Gぐらいまで)
第一世代のCroud SQLでも、規模なWordpressの運用程度なら問題なく利用できるレベルではある
MySQL WorkbenchやNavicatのようなクライアントツールも使用可能
第二世代の場合は下記のメリットがある
MySQL5.5ベース
速度が7~20倍速い
ストレージをオートスケール可能
大抵の場合で第一世代より安く利用できる
なので、特別な理由がなければ第二世代を使えばよい
コンテナエンジンについて
前置き:そもそもコンテナとは
なぜコンテナを使うのか
最近、1つのサービスを1つの環境で用意し、保守性を向上させようという考え方が広まってきた
サービスごとにサーバを立てているとコストがかかるため、仮想環境を用意すると効率が良い
Dockerなどの環境だと、起動が速いので必要な時のみ、サーバ台数を増やすといったスケールアウトが行いやすい
また、Dockerだとイメージを簡単に作れるので、開発と本番で同じ環境を簡単に作ることも可能
Kubernetes
Kubernetesというのは、Dockerイメージの管理ツール
オープンソースで提供されていて、Google内部で10年以上の利用実績がある
GoogleはDockerが出るよりかなり前より、Borgというコンテナサービスの研究を行っていた
コンテナエンジン
コンテナエンジンとは、Kubernetesをgcpで効率よく利用できるようにしたマネージドサービスで、gkeと略される
VMが異常終了したとき、自動で別のサーバに移動させる、ログの管理、VMのモニタリングなどを簡単に行える
gkeでは、Google Container Registryという、Dockerイメージのストレージも用意しています
通常Dockerだとイメージをダウンロードするのに時間がかかりますが、Google Container Registryだとイメージを非常に速く取得できます
Google App Engine Flexible Environmentと似ているサービスですが、Flexible Environmentは1VMあたり1コンテナなのに対して、gkeだと1VMあたり複数コンテナが動作できます
コンピューティングサービス(IaaS)とネットワーク
Google Compute Engine
IaaSでVMを提供するサービスで、AWSのEC2に相当する
インスタンスを起動したまま、ディスクを変更することができる
インスタンスのライブマイグレーション機能があるため、メンテナンス時にサーバを止めなくてよい
課金は1分単位で行われるので、バッチでの計算処理などで30分だけ動作させるといったことも可能
同じVMを使い続ける場合、自動で割引が適用されるので、1日のうちでほとんどの時間稼働させたい場合は、こまめに停止させなくてもよい
Google側に強制終了されてよいようなVMであれば、70%引きで利用できる
ネットワーク
インターネット経由でのアクセス以外に、Googleのデータセンターへ専用線で接続するという選択肢がある
Googleとの回線
Carrier Interconnectを利用
回線提供会社の専用線を利用してGoogleのサービスに接続できる
Cloud VPN
安全性を確保するために社内LANとVPN経由で接続できる
Google Cloud DNS
自分で取得したドメインに対するDNSサービス
ロードバランサ
HTTPベースで負荷分散を行える
スケール可能で、ウォームアップ不要で利用できる
TCPやUDPでもロードバランスできるが、リージョンは同じである必要がある
オペレーションとツール
Stackdriver
モニタリング、ロギング、診断用のサービス
gcpだけでなく、awsも監視できる
オープンソースのエージェントをインストールする
エラーが発生したときは、アラートを出してくれる
アプリログを転送して、検索を行える
Google Cloud Deployment Manager
yamlファイルのテンプレートを用意することで、プロジェクトのひな型を用意できる
Google Cloud Source Repositories Beta
privateなgitリポジトリや、デバッグ機能が用意されている
Google Cloud Functions
AWSのLambdaに相当するサービで、Node.js上で動作するJavascriptを実行可能
ビッグデータと機械学習
BigQuery
大量のデータを高速にオンラインで検索できるようにしたサービス
Googleのの中では人気がある
SQLを使ったクエリが実行可能(RDBでは無い)
ローコストで検索できる
課金額の上限を、アカウント・日別で指定可能で、コスト管理が容易
パフォーマンスが良く、indexを作るなどのパフォーマンスに関するオペレーションが不要
Pub/Sub
メッセージングのサービス
デフォルトで10,000メッセージ/秒のメッセージ送信が可能
Cloud Dataflowなどと組み合わせて使い、データ蓄積のパイプラインの1つとして利用できる
Dataflow
ETL処理など大量のデータを処理するためのサービス
BigQueryは、SQL一回で取得可能な検索は得意だか、手続き的な処理が必要な処理は不得意
このような場合、Pub/Sub経由で送られたデータをDataflowで処理して、データ保存するといったことが可能
バッチ処理、ストリーミングの両方が行える
Java/PythonのSDKが用意されており、これらの言語でプログラミングできる
Google Cloud Dataproc
Googleクラウドの中でMapReduce処理をgcpを利用して行いたい場合のサービス
Haddopクラスタ構築を行う必要がなく、簡単に安価で環境を構築できる
1分単位での課金で、クラスタのノードは高速(90秒以内)に起動できる
データ量に合わせて、何ノードのクラスタが必要かなどのキャパシティプランニングは自分で行う必要がある
Google Cloud Datalab
大量データの可視化をサポートするgcpのサービス
BigQueryや、Compute Engineのデータ,Cloud Strageなどをデータソースで使える
Datalab自体はOpen Sourceで提供されている
Machine Learning
学習のアルゴリズムをTensorFlowで構築する
Cloud MLを利用して学習処理を分散環境で高速に行える
Googleによって既に学習済みのパラメータを使って認識だけを使いたい場合は、Vision API、Speech API, Translate APIなどを利用できる
Speech API
話した文章を文字起こしできるサービス
80の言語を認識でき、リアルタイムで変換できる
Translate API
文章の翻訳を行ってくれるサービス